prepo
Hola,
Nos gustaría crear un tablero para mostrar la mejora en el nivel de madurez en nuestro enfoque DevOps. Los datos están alojados en OneDrive, que está vinculado al servicio PowerBI. He adjuntado datos de muestra en esta publicación, que se actualiza una vez al mes con un nivel único de madurez para cada parámetro. Por ejemplo, los niveles de madurez para
La automatización de control de calidad son:
|
Pruebas automatizadas |
L0. Sin automatización |
|
L1. Automatización sencilla |
|
|
L2. Automatización basada en marcos |
|
|
L3. Automatización programada |
|
|
L4. Integración continua |
|
|
L5. Automatización gestionada |
|
|
Obstruido |
|
|
Administrado por el proveedor |
|
|
N / A |
y para las pruebas de rendimiento son
|
Pruebas de rendimiento |
|
|
L0. Sin rendimiento |
|
|
L1. Rendimiento de usuario único |
|
|
L2. Rendimiento de referencia |
|
|
L3. Rendimiento continuo |
|
|
L4. Rendimiento integrado |
|
|
L5. Rendimiento gestionado |
|
|
Obstruido |
|
|
Administrado por el proveedor |
|
|
N / A |
¿Alguien ha encontrado un caso de uso similar? Se agradece cualquier sugerencia para modelar los datos o representarlos en un informe.
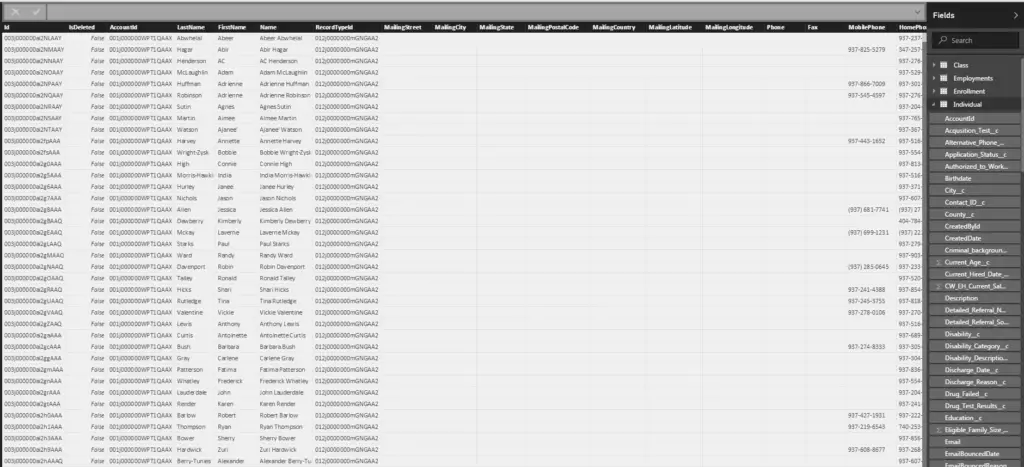
Datos:
abril de 2018
| aplicación | Prioridad | Control de versiones | Integración continua | Pruebas automatizadas – Funcionales | Pruebas automatizadas – Rendimiento | Seguridad: escaneos | Análisis de código | Escaneos de producción | Escaneos de preproducción |
| aplicación 1 | 1 | L2. Git empresarial | Hecho | L2. Automatización basada en marcos | L2. Rendimiento de referencia | Reserva | N / A | Nivel 2 – Equipos: Revisar y arreglar | Nivel 2 – Equipos: Revisar y arreglar |
| aplicación 2 | 3 | L1. Git público | Hecho | L0. Sin automatización | L3. Rendimiento continuo | N / A | Obstruido | Obstruido | N / A |
| aplicación 3 | 3 | L1. Git público | Hecho | L1. Automatización sencilla | L5. Rendimiento gestionado | Obstruido | Obstruido | Obstruido | N / A |
| aplicación 4 | 2 | L1. Git público | En curso | L3. Automatización programada | L1. Rendimiento de usuario único | En curso | En curso | L3. Los escaneos se automatizan a través de la integración continua | L1. Incorporación y escaneo |
| aplicación 5 | 3 | L0. Sin control de versiones | Hecho | L0. Sin automatización | L0. Sin rendimiento | Obstruido | Hecho | Nivel 2 – Equipos: Revisar y arreglar | L4. Seguridad integrada con SDLC |
marzo de 2018
| aplicación | Prioridad | Control de versiones | Integración continua | Pruebas automatizadas – Funcionales | Pruebas automatizadas – Rendimiento | Seguridad: escaneos | Análisis de código | Escaneos de producción | Escaneos de preproducción |
| aplicación 1 | 1 | L1. Git público | Obstruido | L2. Automatización basada en marcos | L1. Rendimiento de usuario único | Reserva | N / A | Nivel 2 – Equipos: Revisar y arreglar | L1. Incorporación y escaneo |
| aplicación 2 | 3 | L1. Git público | Hecho | L0. Sin automatización | L2. Rendimiento de referencia | N / A | Obstruido | Obstruido | N / A |
| aplicación 3 | 3 | L1. Git público | Reserva | L0. Sin automatización | L3. Rendimiento continuo | Obstruido | Reserva | Obstruido | N / A |
| aplicación 4 | 2 | L0. Sin control de versiones | En curso | L2. Automatización basada en marcos | L0. Sin rendimiento | En curso | En curso | L3. Los escaneos se automatizan a través de la integración continua | Obstruido |
| aplicación 5 | 3 | L0. Sin control de versiones | En curso | L0. Sin automatización | L0. Sin rendimiento | Obstruido | Reserva | Nivel 2 – Equipos: Revisar y arreglar | L3. Los escaneos se automatizan a través de la integración continua |
febrero de 2018
| aplicación | Prioridad | Control de versiones | Integración continua | Pruebas automatizadas – Funcionales | Pruebas automatizadas – Rendimiento | Seguridad: escaneos | Análisis de código | Escaneos de producción | Escaneos de preproducción |
| aplicación 1 | 1 | L0. Sin control de versiones | Obstruido | L2. Automatización basada en marcos | L1. Rendimiento de usuario único | Reserva | N / A | Nivel 2 – Equipos: Revisar y arreglar | L1. Incorporación y escaneo |
| aplicación 2 | 3 | L0. Sin control de versiones | En curso | L0. Sin automatización | L2. Rendimiento de referencia | N / A | Obstruido | Obstruido | N / A |
| aplicación 3 | 3 | L1. Git público | Obstruido | L1. Automatización sencilla | L1. Rendimiento de usuario único | Obstruido | Reserva | Obstruido | N / A |
| aplicación 4 | 2 | L0. Sin control de versiones | Reserva | L0. Sin automatización | L0. Sin rendimiento | Reserva | En curso | L1. Incorporación y escaneo | Obstruido |
| aplicación 5 | 3 | L0. Sin control de versiones | En curso | L0. Sin automatización | L0. Sin rendimiento | En curso | Reserva | L1. Incorporación y escaneo | L2. Equipos: revisar y corregir |
-Prepo
v-yulgu-msft
En respuesta a prepo
Hola @prepo,
Como solución alternativa, tal vez pueda usar valores numéricos para representar el nivel de madurez.

Para estas dos tablas, puede agregar una columna condicional que enumere números únicos para cada tipo de nivel. Luego, en la tabla de datos, consulte la columna numérica a través de LOOKUPVALUE para que los valores de texto se conviertan en números. Agregue una columna numérica al gráfico visual.
Saludos,
Yuliana Gu
prepo
En respuesta a v-yulgu-msft
Eso ayudó, gracias por su sugerencia. Por alguna razón, no puedo marcar tu comentario como la solución. notándolo aquí
Como solución alternativa, tal vez pueda usar valores numéricos para representar el nivel de madurez.

Para estas dos tablas, puede agregar una columna condicional que enumere números únicos para cada tipo de nivel. Luego, en la tabla de datos, consulte la columna numérica a través de LOOKUPVALUE para que los valores de texto se conviertan en números. Agregue una columna numérica al gráfico visual.
v-yulgu-msft
Hola @prepo,
Entonces, ¿cuál es el resultado deseado con las tablas de muestra anteriores? Proporcione más descripción sobre su requerimiento.
Saludos,
Yuliana Gu
prepo
En respuesta a v-yulgu-msft
El resultado sería representar visualmente el nivel de madurez mensualmente para cada área por aplicación. Dado que algunas de las aplicaciones tardan varios meses en pasar de un nivel a otro, es imperativo mostrar el estado actual. He representado una muestra de cómo se podrían representar los datos, cualquier consejo es bienvenido. Hazme saber si tienes alguna pregunta.
¡Gracias!

v-yulgu-msft
En respuesta a prepo
Hola @prepo,
En el escritorio de Power BI, no es posible mostrar valores de texto en el eje Y en un gráfico visual. El eje Y solo admite campos numéricos agregados. Me temo que su requisito podría no ser alcanzable en este momento.
Saludos,
yuliana Gu
prepo
En respuesta a v-yulgu-msft
¿Tiene alguna recomendación para convertir dichas matrices para calcular un promedio ponderado y representar el texto en números? ¡Gracias!
v-yulgu-msft
En respuesta a prepo
Hola @prepo,
Como solución alternativa, tal vez pueda usar valores numéricos para representar el nivel de madurez.
Para estas dos tablas, puede agregar una columna condicional que enumere números únicos para cada tipo de nivel. Luego, en la tabla de datos, consulte la columna numérica a través de LOOKUPVALUE para que los valores de texto se conviertan en números. Agregue una columna numérica al gráfico visual.
Saludos,
Yuliana Gu
prepo
En respuesta a v-yulgu-msft
Eso ayudó, gracias por su sugerencia. Por alguna razón, no puedo marcar tu comentario como la solución. notándolo aquí
Como solución alternativa, tal vez pueda usar valores numéricos para representar el nivel de madurez.
Para estas dos tablas, puede agregar una columna condicional que enumere números únicos para cada tipo de nivel. Luego, en la tabla de datos, consulte la columna numérica a través de LOOKUPVALUE para que los valores de texto se conviertan en números. Agregue una columna numérica al gráfico visual.