wjones
Estoy tratando de acceder a los datos de la API de Asana.
Al realizar una llamada a la API para, por ejemplo, «proyectos»,
GET /projects?limit=5&workspace=xxxxxxx
O en PBI,
Json.Document(Web.Contents("https://app.asana.com/api/1.0" & "/projects?" & "limit=5" & "&workspace=xxxxxxx", [Headers=[#"Content-Type"="application/json", Authorization="Bearer somePAT"]]))
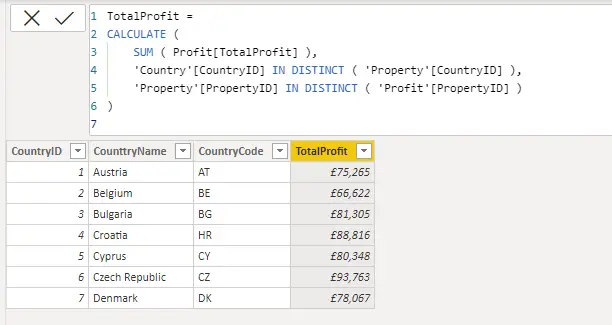
La API responderá con una lista de proyectos y sus atributos, junto con un objeto «next_page» así:
{
"data": [
{
"gid": "12345678910111212",
"name": "Project 1",
"resource_type": "project"
},
{
"gid": "12345678910111213",
"name": "Project 2",
"resource_type": "project"
}
.
.
.
],
"next_page": {
"offset": "someSequence",
"path": "/projects?limit=5&workspace=xxxxxxxx&offset=someSequence",
"uri": "https://app.asana.com/api/1.0/projects?limit=5&workspace=xxxxxxxx&offset=someSequence"
}
}
Obviamente, quiero extraer la lista de proyectos, pero dado que la paginación es obligatoria con un máximo de 100 registros por llamada, necesito una forma de realizar llamadas sucesivamente en función del contenido de «next_page». El «uri» es una API completamente formada, por lo que no es necesario realizar ningún cálculo con compensaciones o límites. Solo necesito poder acceder a los proyectos, extraer el siguiente uri y luego hacer otra llamada usando ese próximo uri. Esto debe suceder hasta que ya no se devuelva «next_page» en la respuesta.
He investigado un poco y aún no he encontrado una solución viable.
¿Cuál es la mejor manera de hacer esto en Power BI? Cualquier sugerencia o fragmentos de código útiles o referencias a la documentación adecuada sería muy apreciada.
================================================
EDITAR:
Desde entonces, he jugado un poco y estoy tratando de usar List.Generate para resolver mi problema. En pseudocódigo, esta es mi intención.
records = {set of records returned from first api call}
while that same call hasNextPage():
build the next api call from the original uri
append the returned records to our existing set of records
Esto es lo que he encontrado hasta ahora
let
uri = "https://app.asana.com/api/1.0/projects?limit=100&workspace=xxxxxxx",
headers = [Headers=[#"Content-Type"="application/json", Authorization="somePAT"]],
//Loop over pages
alldata = List.Generate(
() => Json.Document(Web.Contents(uri, headers))[data],
each hasNextPage(uri),
//how do I change the uri here, to apply the new offset each iteration?
each getRecords(uri & "&offset=" & getNextOffset(uri & "&offset=" & Json.Document(Web.Contents(uri, headers))[next_page][offset]))
),
output = Table.FromList(alldata, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in output
Donde hasNextPage(uri) hace una llamada al uri, luego verifica si el objeto next_page es simplemente nulo, lo que significa el final de las páginas de registros disponibles. getRecords solo devuelve datos sin procesar de la fuente.
let
Source = (uri) => let
Source = Json.Document(Web.Contents(uri, [Headers=[#"Content-Type"="application/json", Authorization="Bearer somePAT"]])),
data = Source[data]
in data
in Source
Esto ahora me da una sola columna llena de listas, cada una de las cuales contiene 100 registros. El problema es que se ejecuta para siempre y devuelve cientos de miles de registros (muchos más de los que DEBERÍAN devolverse). En realidad, nunca carga todas las filas si aplico cambios.
¿Puede alguien ayudarme a depurar la función List.Generate que estoy ejecutando arriba?
wjones
Lo resolvió usando una función recursiva personalizada que toma el desplazamiento, crea el uri de la página siguiente, agrega los datos a un total móvil de los datos, luego realiza otra llamada con el nuevo uri, siempre que exista una página siguiente para llamar.
(baseuri as text) =>
let
headers = [Headers=[#"Content-Type"="application/json", Authorization="Bearer APIKEY"]],
initReq = Json.Document(Web.Contents(baseuri, headers)),
initData = initReq[data],
//We want to get data = {lastNPagesData, thisPageData}, where each list has the limit # of Records,
//then we can List.Combine() the two lists on each iteration to aggregate all the records. We can then
//create a table from those records
gather = (data as list, uri) =>
let
//get new offset from active uri
newOffset = Json.Document(Web.Contents(uri, headers))[next_page][offset],
//build new uri using the original uri so we dont append offsests
newUri = baseuri & "&offset=" & newOffset,
//get new req & data
newReq = Json.Document(Web.Contents(newUri, headers)),
newdata = newReq[data],
//add that data to rolling aggregate
data = List.Combine({data, newdata}),
//if theres no next page of data, return. if there is, call @gather again to get more data
check = if newReq[next_page] = null then data else @gather(data, newUri)
in check,
//before we call gather(), we want see if its even necesarry. First request returns only one page? Return.
outputList = if initReq[next_page] = null then initData else gather(initData, baseuri),
//then place records into a table. This will expand all columns available in the record.
expand = Table.FromRecords(outputList)
in
expand
Esto devuelve una tabla de registros completamente expandida de todas las páginas de datos.
¡Las ampliaciones de funcionalidad o las modificaciones de eficiencia son más que bienvenidas!
ruandeses
Hola,
Tengo el mismo tipo de API (https://manual.yesplan.be/en/developers/rest-api/#pagination), pero me quedo atascado con el «bucle».
Vea a continuación mi código, que se atasca en diferentes páginas cada vez. La mayor parte del tiempo en la página 2, pero a veces en la página 3.
Cuando pruebo la URL (por ejemplo: https://odeon.yesplan.nl/api/events?page=2&book=4758791937&api_key=********) que arroja el error 404 a través de Internet, obtengo más detalles información:
{"contents":{},"message":"Page key "2" is not the current page for the book, which is "3"."}
Cuando luego cambio la página = 2 a la página = 3, obtengo los resultados correctos. Si luego actualizo la página nuevamente, arroja el error anterior una vez más que indica que la página actual debe ser 4. Luego, editar el código a la página = 4 me da la información correcta.
Es casi como si la consulta hiciera una solicitud doble, lo que hace que el índice de la página cambie a 3 donde la consulta aún intenta obtener la página 2.
¿Sabes cómo arreglar ésto?
Ver código:
(baseuri as text) =>
let
initReq = Json.Document(Web.Contents(baseuri)),
initData = initReq[data],
gather = (data as list, uri) =>
let
//get new offset from active uri
newOffset = Json.Document(Web.Contents(uri))[pagination][next],
//build new uri using the original uri so we dont append offsests
newUri = newOffset&"&api_key=**********",
//get new req & data
newReq = Json.Document(Web.Contents(newUri)),
newdata = newReq[data],
//add that data to rolling aggregate
data = List.Combine({data, newdata}),
//if theres no next page of data, return. if there is, call @gather again to get more data
check = if newReq[pagination][next] = null then data else @gather(data, newUri)
in check,
//before we call gather(), we want see if its even necesarry. First request returns only one page? Return.
outputList = if initReq[pagination][next] = null then initData else gather(initData, baseuri),
//then place records into a table. This will expand all columns available in the record.
expand = Table.FromRecords(outputList)
in
expand
Syndicate_Admin
En respuesta a ruandeses
Nota, si cambio esta parte en el código:
check = if newReq[pagination][next] = null then data else @gather(data, newUri)
A esto:
check = if newReq[pagination][next] = null then data else data
Solo se repetirá una vez, ya que eliminé el ciclo recurrente. Luego obtendré las primeras 200 filas (que son 2 páginas, 100 filas por página). Entonces parece que en la parte del bucle está usando la URL incorrecta/antigua[pagination][next].
Alguna idea de como arreglar esto?
ruandeses
En respuesta a ruandeses
Nota, si cambio esta parte en el código:
check = if newReq[pagination][next] = null then data else @gather(data, newUri)
A esto:
check = if newReq[pagination][next] = null then data else data
Solo se repetirá una vez, ya que eliminé el ciclo recurrente. Luego obtendré las primeras 200 filas (que son 2 páginas, 100 filas por página). Entonces parece que en la parte del bucle está usando la URL incorrecta/antigua[pagination][next].
Alguna idea de como arreglar esto?
wjones
Lo resolvió usando una función recursiva personalizada que toma el desplazamiento, crea el uri de la página siguiente, agrega los datos a un total móvil de los datos, luego realiza otra llamada con el nuevo uri, siempre que exista una página siguiente para llamar.
(baseuri as text) =>
let
headers = [Headers=[#"Content-Type"="application/json", Authorization="Bearer APIKEY"]],
initReq = Json.Document(Web.Contents(baseuri, headers)),
initData = initReq[data],
//We want to get data = {lastNPagesData, thisPageData}, where each list has the limit # of Records,
//then we can List.Combine() the two lists on each iteration to aggregate all the records. We can then
//create a table from those records
gather = (data as list, uri) =>
let
//get new offset from active uri
newOffset = Json.Document(Web.Contents(uri, headers))[next_page][offset],
//build new uri using the original uri so we dont append offsests
newUri = baseuri & "&offset=" & newOffset,
//get new req & data
newReq = Json.Document(Web.Contents(newUri, headers)),
newdata = newReq[data],
//add that data to rolling aggregate
data = List.Combine({data, newdata}),
//if theres no next page of data, return. if there is, call @gather again to get more data
check = if newReq[next_page] = null then data else @gather(data, newUri)
in check,
//before we call gather(), we want see if its even necesarry. First request returns only one page? Return.
outputList = if initReq[next_page] = null then initData else gather(initData, baseuri),
//then place records into a table. This will expand all columns available in the record.
expand = Table.FromRecords(outputList)
in
expand
Esto devuelve una tabla de registros completamente expandida de todas las páginas de datos.
¡Las ampliaciones de funcionalidad o las modificaciones de eficiencia son más que bienvenidas!
wes2015
En respuesta a wjones
Hola @wjones, esto parece algo que podría usar en mi caso.
Tomé prestado su script y lo apliqué a la API con la que estoy trabajando, pero me topé con una pared cuando finalizó el bucle.
Sospecho que esto tiene algo que ver con el hecho de que cuando no hay más resultados, la API no devuelve la parte «next_page» del JSON, simplemente no está allí.
Cuando se ejecuta la API con un límite de 1, la paginación está ahí

Cuando se ejecuta con un límite de 100 (hay 33 filas en la base de datos de demostración), la parte de «paginación» desaparece

He jugado con una solución de probar/de lo contrario, pero simplemente no funciona.
¿Tuviste el mismo problema?
Wes
wjones
En respuesta a wes2015
Esto no es algo con lo que tuve que lidiar porque la API que estaba usando devuelve «next_page: null» una vez que hemos agotado todos los datos en lugar de no devolver nada. Dicho esto, todo lo que debe hacer es modificar mi condición de parada
check = if newReq[next_page] = null then data else @gather(data, newUri)
y el verificador de solicitud inicial
outputList = if initReq[next_page] = null then initData else gather(initData, baseuri),
para comprobar si el paginación La clave está contenida en el json. Es posible que pueda hacerlo con el manejo de errores de la forma en que lo ha estado intentando, pero por encima de mi cabeza, también podría intentar convertir el json en texto normal y luego usar Text.Contains para ver si «»paginación»: { » existe como una subcadena.
wes2015
En respuesta a wjones
Gracias, sí, arreglé la condición de parada para buscar la columna «paginación» como se muestra a continuación, y la consulta se ejecuta sin errores ahora.
Pero aún no está devolviendo más de 100 filas.
La parte List.Contains ( Table.ColumnNames() funciona por sí misma en una consulta independiente, pero no estoy seguro de cómo verificar si funciona dentro de la condición de parada dentro de la función «recopilar».
¿Ves algún defecto importante?
let
baseuri = "https://api.hubapi.com/crm/v3/objects/contacts
limit=100&archived=false&hapikey=" & apikey ,
//headers = [Headers=[#"Content-Type"="application/json", Authorization="Bearer " & apikey ]],
initReq = Json.Document(Web.Contents(baseuri)),
#"Converted to Table" = Record.ToTable(initReq),
initData = initReq[results],
//We want to get data = {lastNPagesData, thisPageData}, where each list has the limit # of Records,
//then we can List.Combine() the two lists on each iteration to aggregate all the records. We can then
//create a table from those records
gather = (data as list, uri) =>
let
//get new offset from active uri
newOffset = Json.Document(Web.Contents(uri))[paging][next][after],
//build new uri using the original uri so we dont append offsests
newUri = baseuri & "&after=" & newOffset,
//get new req & data
newReq = Json.Document(Web.Contents(newUri)),
newdata = newReq[results],
//add that data to rolling aggregate
data = List.Combine({data, newdata}),
//if theres no next page of data, return. if there is, call @gather again to get more data
check = if List.Contains ( Table.ColumnNames(newReq as table), "paging" ) = true then @gather(data, newUri) else data
in
check,
//before we call gather(), we want see if its even necesarry. First request returns only one page? Return.
outputList = if List.Contains (Table.ColumnNames( #"Converted to Table" as table) , "paging" ) = true then gather(initData, baseuri) else initData,
//then place records into a table. This will expand all columns available in the record.
expand = Table.FromRecords(outputList)
in
expand
biancag
En respuesta a wjones
Hola,
Soy un novato en las paginaciones API. Este código es el más fácil de seguir en la paginación que he encontrado.
Cuando copio el código y actualizo las credenciales, aparece el siguiente error. ¡¡Por favor ayuda!!

Gracias, bianca
wjones
En respuesta a biancag
Hola Bianca, ¡no todas las API están construidas de la misma manera! Según la API, el json de salida tendrá una estructura diferente y es posible que no tenga un campo «next_page». Debe averiguar cómo su API maneja la paginación y modificar el código en consecuencia. Agregue algunos detalles sobre la API que está utilizando y tal vez pueda ayudar
igorop
En respuesta a wjones
@wjones muchas gracias!! este código me ayudó mucho!
¡Gracias a usted, aprendí una nueva forma de paginar solicitudes de API en Power Query!
¡Excelente trabajo! ¡¡Felicidades!!
mahoneypat
Por favor vea este video para una manera de hacer esto.
Power BI – Historias desde el frente – API REST – YouTube
Saludos,
Palmadita
wjones
En respuesta a mahoneypat
¡Gran video! Desafortunadamente, lo que explica solo funciona si puede predeterminar conteos y compensaciones. No me dan un «recuento total» en el que pueda basar solicitudes sucesivas. Cada solicitud devuelve una página siguiente, que me da el siguiente token de desplazamiento aleatorio:
"next_page": {
"offset": "yJ0eXAiOiJKV1QiLCJhbGciOiJIRzI1NiJ9",
"path": "/projects?limit=5&workspace=xxxxxxxx&offset=yJ0eXAiOiJKV1QiLCJhbGciOiJIRzI1NiJ9",
"uri": "https://app.asana.com/api/1.0/projects?limit=5&workspace=xxxxxxxx&offset=yJ0eXAiOiJKV1QiLCJhbGciOiJIRzI1NiJ9"
}
Entonces, para cada solicitud, necesito extraer los datos reales en un table así como tomar el desplazamiento (o más fácilmente, el uri completamente construido) y agregar los datos devueltos a la misma tabla.
En python, solo tendría un ciclo para ejecutar cada devolución de json, tomar el desplazamiento y hacer la siguiente llamada. Esa es la funcionalidad que me gustaría aquí, pero tengo problemas para traducirla a un lenguaje funcional como M/PQ.
mahoneypat
En respuesta a wjones
Si sabe cuántos esperar, puede codificarlo en la función List.Numbers (si no puede usar dinámicamente un $count para obtenerlo). También puede pasarlo y ver qué llamadas tienen errores o están vacías.
Palmadita
wjones
En respuesta a mahoneypat
Como dije anteriormente, no tengo la capacidad de averiguar de manera preventiva un recuento de los registros existentes. Solo necesito hacer la llamada continuamente, verificar si hay una compensación en next_page, luego agregar esa compensación a mi uri y repetir hasta next_page = null en el json devuelto.
He hecho algunas modificaciones a mi pregunta original. ¿Podrías echar un vistazo a eso? Confío en List.Generate y tengo algunos problemas.