Anónimo
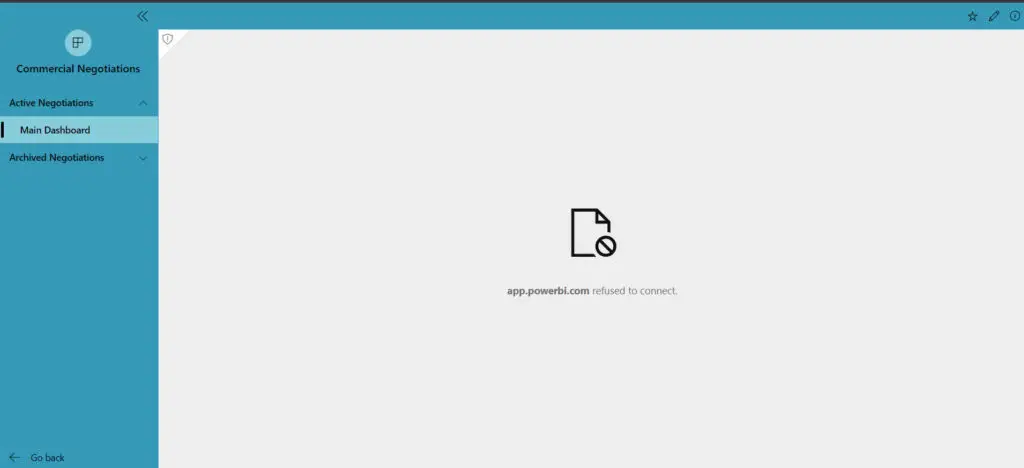
¿Solo verificando si otros usuarios de Premium están experimentando este error de forma intermitente durante los últimos días? He fallado algunas actualizaciones con este mensaje. Las actualizaciones posteriores de los modelos funcionan bien, por lo que no es gran cosa (hasta ahora).
Nuestra capacidad está en el sudeste asiático, en caso de que sea relevante para otros usuarios que también tengan problemas. Hasta ahora no hay nada relevante en la página de soporte aquí:
https://powerbi.microsoft.com/en-us/support/
rubymaya
Hola,
Tuve este mismo error con mi actualización de flujo de datos hoy:
PipelineException: el contenedor salió inesperadamente con el código 0x0000DEAD. PID: 6692.
El flujo de datos está en el mismo espacio de trabajo que los informes. ¿Hay alguna interrupción?
V-lianl-msft
Hola @Anónimo,
¿Ocurre el problema cuando actualiza el flujo de datos?
Por favor, intente las siguientes sugerencias:
Hay una diferencia semántica cuando se hace referencia a las entidades desde DF en el mismo espacio de trabajo y cuando DF es un espacio de trabajo diferente con respecto al motor de cómputo. En el mismo caso de espacio de trabajo, los flujos de datos tienen una fuerte referencia entre sí y se actualizan en la misma transacción. Por lo tanto, no necesitamos almacenar datos en caché y podemos referirnos a los datos de la entidad ascendente. Sin embargo, cuando provienen de un espacio de trabajo diferente, las referencias son referencias débiles y, para ser independientes dentro de un espacio de trabajo, necesitamos volver a almacenar en caché los datos. El paso de volver a almacenar en caché es lo que agrega el tiempo adicional en el procesamiento.
Para mitigar esto sugerimos
- Aumente el porcentaje máximo de memoria de los flujos de datos y disminuya el porcentaje máximo de memoria de los conjuntos de datos en la misma cantidad. (Si tienen configuraciones predeterminadas, aumente los flujos de datos al 40 % y reduzca los conjuntos de datos al 80 %).
- Aumente el tamaño del contenedor de flujos de datos a 1500 Mb. Esto reducirá el paralelismo y potencialmente reducirá las fallas intermitentes.
Atentamente,
Liang
Si esta publicación le ayuda, considere aceptarla como la solución para ayudar a los otros miembros a encontrarla más rápidamente.
Anónimo
En respuesta a V-lianl-msft
Hola, @V-lianl-msft, no usamos flujos de datos porque no hemos encontrado un caso de uso que los haga superiores a Power Query, para nuestras necesidades. El problema no ha persistido en las últimas 24 horas, así que lo que sea que estaba mal ya pasó.
El consumo general de recursos de la capacidad también se ha visto completamente normal. Lo que sea que estaba mal, se ha ido ahora y no hay rastro del problema. El único punto en común era el tiempo. Todos los informes parecían tener éxito y fallar en momentos similares del día. La hora del día fue consistente, justo cuando 1 informe falló, otros a la misma hora también fallaron. Más tarde en el mismo día tendrían éxito.

V-lianl-msft
En respuesta a Anónimo
Hola @Anónimo,
Le sugiero que cree un ticket de soporte o envíe su problema.

Atentamente,
Liang
Si esta publicación le ayuda, considere aceptarla como la solución para ayudar a los otros miembros a encontrarla más rápidamente.
Anónimo
En respuesta a V-lianl-msft
@ V-lianl-msft eso es innecesario ya que el problema se resolvió solo.