ChrisWilliams
Estoy trabajando en una función RANKX que involucra un filtro. Revisé esta respuesta, pero no pareció ayudar a mi escenario.
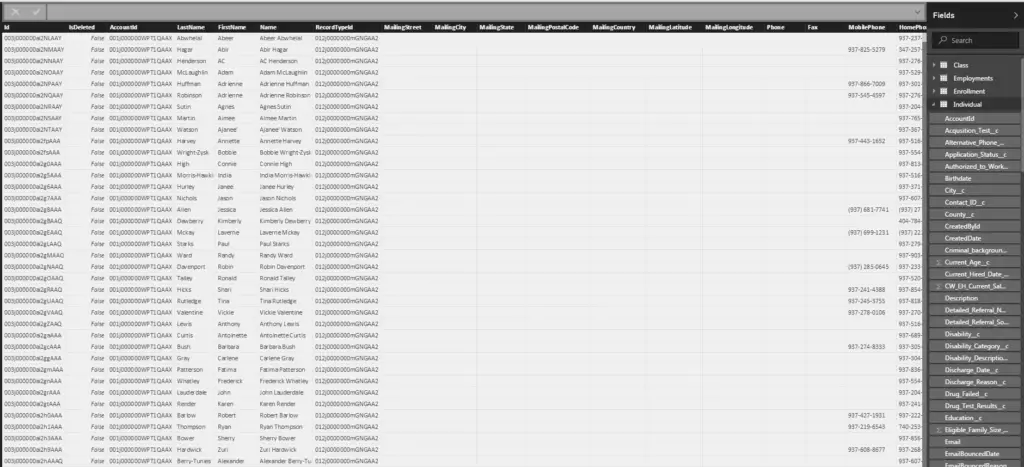
Tengo una tabla llamada «UserMessages», y a continuación se muestra una versión simplificada:

Básicamente, quiero clasificar a los usuarios como «Remitentes principales» o «Receptores principales». Cuando son un remitente principal, la clasificación se basa en el filtrado de la columna Dirección a «Saliente».
Creé un mensaje llamado «Clasificar remitentes principales» y tiene este aspecto:
Clasificar remitentes principales = RANKX (FILTER (ALL (UserMessages), UserMessages[Direction] = «Saliente»), SUM (UserMessages[Messages]) ,, DESC, denso)
Sin embargo, no parece clasificarse correctamente, porque cada usuario se muestra con una clasificación de 1

He probado varias variaciones, pero si alguien me puede indicar la dirección correcta, lo agradecería.
Vvelarde
hola @ChrisWilliams
Rank Top Senders =
RANKX (
FILTER ( ALL ( UserMessages ); UserMessages[Direction] = "Outbound" );
CALCULATE (
SUM ( UserMessages[Messages] );
ALLEXCEPT ( UserMessages; UserMessages[User] )
);
;
DESC;
DENSE
)
reemplazar ; con ,
Vvelarde
hola @ChrisWilliams
Rank Top Senders =
RANKX (
FILTER ( ALL ( UserMessages ); UserMessages[Direction] = "Outbound" );
CALCULATE (
SUM ( UserMessages[Messages] );
ALLEXCEPT ( UserMessages; UserMessages[User] )
);
;
DESC;
DENSE
)
reemplazar ; con ,
Anónimo
En respuesta a Vvelarde
Hola Chris,
He estado buscando ayuda en mi desafío y me encuentro con esta publicación. Intenté modificar su solución a mi situación, pero de alguna manera no funciona. Mi situación es un poco diferente.
A continuación se muestra una tabla simplificada. Lo que quiero es clasificar el nombre del cliente por ventas, PERO EXCLUYENDO a todos los clientes con nombres en blanco (llamémoslos clientes anónimos).
La fórmula que se me ocurrió después de modelar la tuya es:
Gracias por la ayuda.
PBISean
| Nombre del cliente | Ventas | Núm. De orden de venta |
| A | 800 | 1 |
| B | 700 | 2 |
| C | 600 | 3 |
| D | 500 | 4 |
| mi | 400 | 5 |
| 300 | 6 | |
| F | 200 | 7 |
| GRAMO | 100 | 8 |
| A | 80 | 9 |
| B | 70 | 10 |
| C | 60 | 11 |
| D | 50 | 12 |
| mi | 40 | 13 |
| 30 | 14 | |
| F | 20 | 15 |
| GRAMO | 10 | dieciséis |
Ashish_Mathur
En respuesta a Anónimo
Hola,
Puede arrastrar el Nombre del cliente a las etiquetas de las filas y luego, en los filtros de nivel visual, desmarque el espacio en blanco en el campo Nombre del cliente. Escribe estas medidas
Ventas totales = SUM (Datos[Sales])
Anónimo
En respuesta a Ashish_Mathur
Ashish_Mathur,
Gracias por tu ayuda. Funciona con mis datos simulados, pero no con mi conjunto de datos reales, que tiene 1,3 millones de líneas. No estoy seguro de por qué. Pasaré algún tiempo mañana tratando de solucionar problemas. Solo quiero darte las gracias primero.
PBISean
Ashish_Mathur
En respuesta a Anónimo
De nada.
Vvelarde
En respuesta a Anónimo
@Anónimo
Hola, una forma sencilla es usar una medida para clasificar (básico) y un filtro de nivel visual para excluir espacios en blanco.
Si tiene problemas con el filtro, puede crear una nueva medida
MeasuretoexcludeAnonymus = Len (Table1[ClientName])
y utilícelo en el filtro de nivel visual para excluir el 0.
Saludos
Víctor
ChrisWilliams
En respuesta a Vvelarde
Gracias @Vvelarde, eso funciona perfectamente. Tendré que estudiar AllExcept … No he visto que se use en Ranking antes, pero funciona bien.