Greg_Deckler
Introducción
El tiempo medio entre fallas (MTBF) es un término y concepto común que se utiliza en contextos de mantenimiento de equipos y plantas. Además, el MTBF es una consideración importante en el desarrollo de productos. MTBF, junto con otra información de mantenimiento, reparación y confiabilidad, puede ser extremadamente valioso para las organizaciones para ayudar a identificar sistemas problemáticos, predecir interrupciones del sistema, mejorar los diseños de productos y mejorar la eficiencia y efectividad operativa general. Como tal, sería beneficioso comprender cómo implementar esta métrica dentro de Power BI.
Fondo
MTBF es esencialmente el tiempo medio aritmético entre fallas de un sistema. Ahora bien, la definición de falla dependerá en gran medida de la circunstancia en la que se aplique esta métrica pero, en general, las fallas que no ponen el sistema fuera de servicio generalmente no se consideran fallas. Además, las tareas de mantenimiento de rutina que están programadas generalmente tampoco se consideran fallas.
La siguiente imagen de esta página de Wikipedia probablemente hace un trabajo tan bueno como cualquier otro en la representación de MTBF.

En el lenguaje matemático formal, MTBF se define como:

¡Vamos a construirlo!
De acuerdo, suficiente historia y antecedentes, ¡construyamos este cachorro!
Paso 1: prepare sus datos
Entonces, generé algunos datos falsos que puedes descargar aquí. Los datos tienen un poco más de 4.000 filas y representan 3 años de datos de reparación para una docena de «máquinas». Estos datos son bastante básicos, pero tienen los elementos esenciales que necesitaremos para demostrar la técnica. Cada fila representa una única reparación. Así es como se ven los datos:

Entonces, esencialmente tenemos un identificador para la máquina, cuándo comenzó la reparación, cuándo terminó la reparación, el tipo de reparación (una reparación o mantenimiento preventivo (PM)) y la causa de la reparación.
Paso 2: cargar en Power BI y crear campos calculados
Este siguiente paso es fácil, simplemente inicie Power BI Desktop y desde el Hogar pestaña de la cinta, elija Obtener datos | Sobresalir. Señale el archivo de datos que acaba de descargar (arriba) y elija la Hoja (MTBF) o la Tabla (MTBF1) que se muestra en la navegación y elija Carga.
A continuación, crearemos dos columnas calculadas. El primero es cuánto tiempo tardó en completarse la reparación. La fórmula para esto es:
Horas de reparación = DATEDIFF (Reparaciones[RepairStarted], Reparaciones[RepairCompleted], SEGUNDO) / 3600
Una vez que cree esta columna, en el Modelado lengüeta de la cinta, asegúrese de que Tipo de datos se establece en Número decimal y que especifique al menos 2 lugares decimales.
Obviamente, todo lo que estamos haciendo es restar el tiempo que comenzó la reparación desde el momento en que se completó la reparación, de modo que terminemos con el tiempo que tardó en completarse. Quizás menos obvio es el motivo por el que especificamos SEGUNDO en lugar de HORA en nuestra función DATEDIFF aunque queremos esta métrica en horas y, por lo tanto, la división por 3600 segundos / hora. La razón es que si hubiéramos especificado HORA, entonces DATEDIFF habría truncado el cálculo a horas enteras y habríamos perdido fracciones de hora.
La segunda columna calculada es un poco más compleja:
Tiempo de actividad =
VAR siguiente = MINX (FILTRO (Reparaciones,
Refacción[MachineName]= ANTES (Reparaciones[MachineName]) &&
Refacción[RepairStarted]> ANTES (Reparaciones[RepairStarted]) &&
Refacción[RepairType]<> «PM»
),Refacción[RepairStarted])
REGRESAR SI ([RepairType]= «PM», 0, SI (ESBLANCO (siguiente),
DATEDIFF ([RepairCompleted], AHORA (), SEGUNDO),
DATEDIFF ([RepairCompleted], siguiente, SEGUNDO)
)
)
Bien, déjame explicarte lo que está pasando aquí. Recuerde de nuevo nuestra definición de MTBF, necesitamos encontrar el tiempo de actividad entre una máquina que entra en un estado «activo» y esa misma máquina que entra en un estado «inactivo». Pero nuestros datos no están estructurados de esa manera, los datos se centran en recopilar información de reparación.
Así, la primera parte de la fórmula, la porción VAR es el cálculo de la variable Siguiente. Se trata de encontrar la siguiente reparación después de la reparación actual. Hacemos esto encontrando el MIN de la columna RepairStarted después de filtrar nuestra tabla Repair para máquinas que son iguales a la máquina actual en la fila, además de tener un RepairStarted que es posterior a la reparación actual en la fila y estamos excluyendo «PM» filas, ya que son mantenimiento preventivo y no una falla real.
La segunda parte de la fórmula, la parte de DEVOLUCIÓN, consta en realidad de tres partes. Si la fila actual es una tarea de mantenimiento (PM), devolvemos 0 para el tiempo de actividad, ya que no queremos que esas tareas se incluyan en nuestro cálculo de MTBF. Si nuestro cálculo para el siguiente es EN BLANCO, entonces sabemos que esta es la falla más reciente en nuestro conjunto de datos. Entonces, devolvemos la diferencia en segundos entre AHORA y la finalización de la falla actual. Finalmente, si ninguno de esos es el caso, simplemente calculamos la diferencia en segundos entre el momento en que comenzó nuestra próxima reparación y la finalización de la reparación actual.
Paso 3: crea algunas medidas
Bien, ahora que tenemos nuestros datos cargados y hemos creado algunas columnas calculadas adicionales, ahora podemos crear las medidas que usaremos en nuestro informe. Cree las siguientes medidas:
- Reparaciones = CALCULAR (COUNTROWS (Reparaciones), FILTRO (Reparaciones,[RepairType]<> «PM»))
- MTBF (Horas) = DIVIDE (SUM (Reparaciones[Uptime]),[Repairs], EN BLANCO ()) / 3600
- MDT (Horas) = SUM (Reparaciones[Repair Hours]) / COUNTROWS (Reparaciones)
- Última reparación = MAX ([RepairCompleted])
- Próxima reparación esperada = [Last Repair] + [MTBF (Hours)]/ 24
Refacción: Este es el número total de reparaciones que se han realizado, excluidas las reparaciones de mantenimiento preventivo (PM).
MTBF: Este es nuestro cálculo de MTBF que toma la suma de nuestro tiempo de actividad en segundos, lo divide por el número de reparaciones para obtener un promedio y luego convierte el número en horas dividiéndolo por 3600 segundos / hora.
MDT: Esta es una medida que a menudo se asocia con MTBF, MDT es el tiempo medio de inactividad o la cantidad promedio de tiempo que tarda una reparación en completarse. Por lo tanto, tomamos la suma de nuestras horas de reparación (que no excluye las tareas de mantenimiento preventivo) y la dividimos por el recuento de todas las reparaciones. Tenga en cuenta que no usamos la medida de Reparaciones en este caso ya que queremos incluir también las reparaciones de PM.
Última reparación: Esta es simplemente la fecha / hora de nuestra última reparación.
Próxima reparación esperada: Al saber cuándo ocurrió nuestra última reparación, podemos agregar nuestro cálculo de MTBF convertido a días (/ 24) para determinar cuándo esperamos que ocurra nuestra próxima falla.
Paso 4: Genere el informe
Ahora que hemos creado todas nuestras medidas, es un juego de niños crear un informe similar al siguiente:

Dejé todo por defecto para que las propias imágenes muestren qué columnas y medidas se muestran. Incluso este informe altamente simplificado muestra información valiosa sobre cada una de nuestras máquinas, los tipos de fallas que experimentan y, debido a que usamos medidas, todo es interactivo. Por ejemplo, si hacemos clic en «Componente gastado» en el gráfico de barras del medio:

Podemos ver que las fallas causadas por componentes desgastados ocurren con mucha menos frecuencia que el promedio (un MTBF de 300 frente a 199 para todos los tipos de fallas) y tardan aproximadamente la mitad del tiempo en completarse (MDT de 1.23 frente a 2.19 para todos los tipos de fallas).
Conclusión
Aparte de una columna calculada de DAX potencialmente compleja, es extremadamente fácil y directo usar Power BI para crear informes que resuman la información de reparación, incluido el MTBF. Y recuerde que la definición de «fracaso» puede ser subjetiva y se puede aplicar creativamente a otros dominios temáticos. Este ejemplo aquí realmente se basa en tener una hora de inicio y una hora de finalización para «algo». Entonces, ¿podría esto aplicarse a algo como los datos de recursos humanos y las fechas de inicio y finalización? Claro, considere cada terminación y «falla» y el MTBF podría arrojar luz sobre el tiempo promedio que se tarda en completar una posición. Las posibilidades son infinitas, así que empiece a utilizar esta técnica en sus propias situaciones en Power BI.
21
Greg_Deckler
Contador de seguimiento agregado:
0
JasonM
Esto fue realmente genial. Gracias por tu publicación.
Tengo un caso de uso para esto, pero tengo un problema porque para una ‘máquina’ determinada podría tener más de un registro de reparaciones.
RepairStart, RepairEnd, Categoría, Ubicación, Máquina
1/1/2018 2:40 a. M., 1/1/2018 4:15 a. M., Caída del sistema operativo, Seattle, servidor 1
1/1/2018 3:12 a.m., 1/1/2018 2:15 a.m., caída del sistema operativo, Seattle, servidor 1
Entonces, una reparación comenzó después de la primera, pero se resolvió antes de la segunda.
Me he equivocado con algunas cosas, pero todavía obtengo muchos valores negativos para MTBF y ‘Uptime’.
Intenté hacer una nueva clave de fila combinando Categoría, Ubicación, Máquina. Pero no me ha dado lo que busco, por lo que agradecería alguna aportación si alguien ve esto y podría entender lo que está pasando un poco mejor que yo.
¡Salud!
2
Anónimo
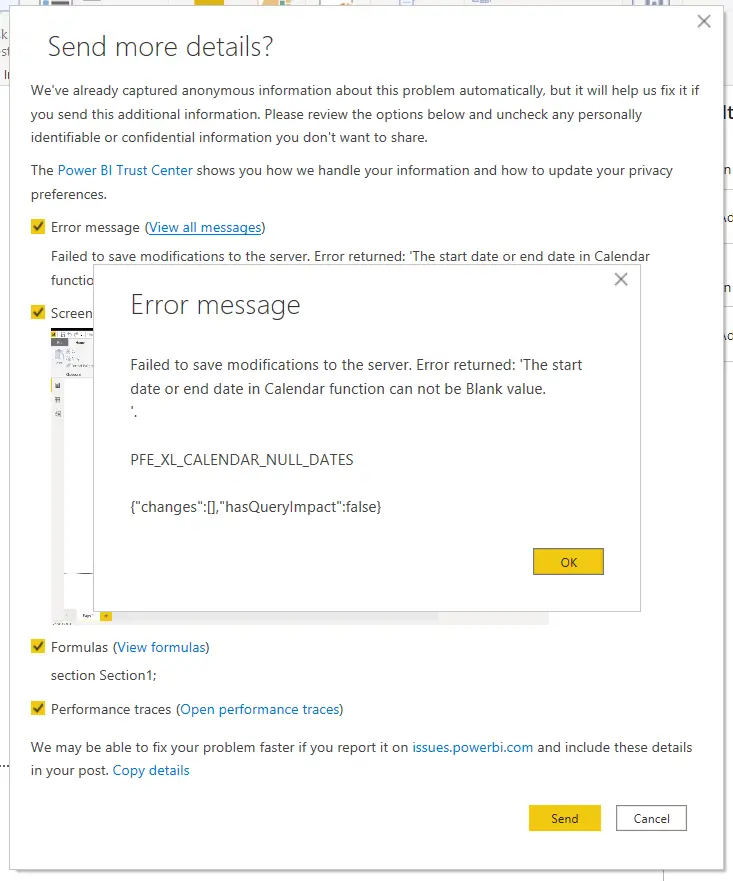
Buenos días, estoy siguiendo todos los pasos de las instrucciones y aparece el error «La sintaxis de ‘SI’ es incorrecta».
¿Podrías decirme en qué me equivoco?

¡Saludos! Gracias.
Javier.-
3
rajendraongole1
Buen articulo. gracias por la orientación y las prácticas.
2
AdamPSP
Si hubiera varias máquinas que no estuvieran siempre encendidas a la vez, sino en un horario, ¿podría expandirse este seguimiento de reparaciones para rastrear solo las máquinas «encendidas» durante su período de programación: programaciones semanales o quincenales? Si sé cuándo una máquina está «encendida» a partir de un programa (fecha y hora de la tabla de inicio y parada), ¿podría aplicarse esto de modo que las diversas medidas solo se apliquen a las computadoras «en»?
¿Funcionaría esto también para monitorear un registro de llamadas cuando los empleados están en una llamada en lugar de en una llamada durante un período de trabajo programado con un horario predeterminado?
0
Greg_Deckler
@AdamPSP No veo nada específico sobre por qué esto no funcionaría en los escenarios que enumeró. Sin embargo, necesitaría comprender mejor sus datos para determinar exactamente cómo adaptaría este enfoque.
1
AdamPSP

@Greg_Deckler Usando su ejemplo en la publicación, pude aplicarlo para rastrear la duración del tiempo de tareas específicas del personal y la duración del tiempo cuando el personal no está realizando una tarea (esta primera parte funciona muy bien para lo que estoy tratando de medir ). El desafío que tengo es que el personal está en períodos de vigilancia, por lo que no siempre está activo como en el ejemplo de su máquina. Solo quiero medir entre un período de tiempo: OnWatch y OffWatch para cada persona (Máquina). Tengo una hoja de cálculo de fecha y hora para cuando las personas (MachineName) comienzan y terminan un ciclo de vigilancia (OnWatch, OffWatch).
Me gustaría que esta tabla fuera parte del período de tiempo en el que se toman las medidas. De lo contrario, las medidas se desvían porque las medidas están calculando un período de tiempo en el que la persona (máquina) no está realmente en Vigilancia. ¿Cómo implementaría una tabla (como se describe arriba) para que la medición tenga en cuenta?
0
Greg_Deckler
@AdamPSP Pude ver un par de enfoques diferentes para esto, podría filtrar su tabla de datos solo a las filas donde la máquina está «en vigilancia» y luego hacer su cálculo. O bien, puede hacerlo en la columna y, como parte del cálculo, verifique si cae en un período de «vigilancia».
0
AdamPSP
@Greg_Deckler Gracias por volver a esta pregunta. Soy nuevo en Power BI y en cómo funcionarían los distintos filtros para este ejemplo, así que discúlpeme si me falta algo aparentemente simple.
En última instancia, quiero medir usando su cálculo de «tiempo de actividad» solo para el período de tiempo que una persona o personas (máquinas) están «de guardia». Dado que las personas (máquinas) tienen varios horarios de OnWatch y OffWatch, creo que este cálculo debe realizarse utilizando una tabla de la fecha y hora programada real frente a una establecida.
En la imagen de abajo, cada máquina tendría una fecha y hora de inicio diferentes para los períodos «OnWatch & OffWatch». Durante este período de tiempo de vigilancia (aproximadamente 15 días), habría tiempo de actividad y fallas para cada máquina. Solo me gustaría medir las máquinas disponibles (en guardia) por su tiempo de actividad y fallas.

1
Sergio_Reese
Hola @Greg_Deckler, tengo una pregunta sobre el uso de esta fórmula. Con los datos que estoy usando tengo diferentes máquinas y diferentes equipos que corresponden a cada máquina, esta fórmula funciona muy bien al filtrar la columna de Máquina y Equipo, pero no funciona al filtrar solo la máquina, por ejemplo si quiero ver tiempos entre las fallas de todos los equipos en la máquina uno.
Quiero saber si es posible hacer este tipo de filtrado para obtener estos datos porque lo que estoy tratando de hacer es cambiar la etiqueta de «Máquina y equipo» a solo «Máquina» pero no funciona, obtengo mucho de ceros y tiempos equivocados.
Agrego esta tabla como ejemplo y espero haber podido explicarme con mi pregunta.

Gracias por tu tiempo
0
Anónimo
hola @Greg_Deckler
Tu publicación es realmente útil, sería bueno. Si comparte con nosotros el archivo pbix del informe. Apreciaría tu ayuda. Gracias.
0
Greg_Deckler
@Anónimo De hecho, tengo una versión mejorada de esto en mi libro, DAX Cookbook. Puede descargar el PBIX aquí: https://github.com/gdeckler. Es el Capítulo 9, Receta 2.
1
Anónimo
@Greg_Deckler Muchas gracias, pero la receta 2 del capítulo 9 es un informe de ventas. ¿Puedes comprobarlo dos veces?
0
Greg_Deckler
@Anónimo Lo comprobé dos veces. Quieres este archivo:
DAXCookbook / Chapter09.pbix en master · gdeckler / DAXCookbook (github.com)
Y Receta 02 página
1
johnyounie
Hola @Greg_Decler
Publicación realmente interesante, yo era un científico de datos en la RAF y escribimos modelado de repuestos y simulaciones de monte carlo en FORTRAN para monitorear las fallas de sistemas costosos (aviones, barcos, vehículos) y para simular el uso de esos sistemas.
Terminamos usando software propietario escrito por un nombre de empresa TFDG (www.tfdg.com) en los EE. UU. (Divulgación completa, los contraté una vez que dejé la RAF como programador) y tienen software que llevará a cabo estos cálculos para sistemas denominados VMetric, Edcas y MAAP (y otros).
Además, para fines de equilibrio, existe una empresa sueca llamada Systecon que produce un software similar que también usamos llamado Opus, que era un poderoso paquete de software de modelado de repuestos.
Hay un libro del Dr. Craig Sherbrooke (famoso por RAND y VariMetric Craig C. Sherbrooke | RAND y Craig C Sherbrooke – Home (acm.org)) que se llama Optimal Inventory Modeling of Systems ISBN: 0-471-55838-9 Publisher John Wiley and Sons, que describe las técnicas y los algoritmos para producir dicho modelo. Lo incluyo aquí en caso de que las personas que lean tu publicación estén interesadas. Craig es un tipo increíble y tuve la suerte de conocerlo unas cuantas veces, dos veces en sus cursos de formación, también me ayudó con mi disertación para mi licenciatura.
Ambos utilizan la distribución de Poisson (Wikipedia: Poisson expresa la probabilidad de que un número determinado de eventos ocurran en un intervalo fijo de tiempo o espacio si estos eventos ocurren con una tasa media constante conocida e independientemente del tiempo transcurrido desde el último evento.) y se clasifican como multiescalón y multisistema .
Espero que alguien encuentre esto útil e interesante, podría continuar, pero sé cuándo parar (es cuando escucho ronquidos :-)).
Si alguien quiere conectarse, puede encontrarme en
John Younie (BSc (Hons), MCSE, MCAD, MCT, MOS Master) | LinkedIn
Salud
John
0